
Классификация авто — BEREZA DETAILING
| 1 класс | 2 класс | 3 класс | 4 класс | |
|---|---|---|---|---|
| ASTON MARTIN | Rapide, Vantage, DB, Lagona, Vanquish, Vulcan | |||
| AUDI | A4, Q3 | A1, A2, A3, A5, A6, A7, A8, Q5, Q7, Q8, TT, R8, RS6, Allroad | ||
| BMW | 1, 2 | 3, 4, 5, 6, M2, Z4, Z3, X1, X3, X4 | Z8, X6 | X5, 7, X7 |
| BENTLEY | Arnage, Continental GT, Flying Spur, Mulsanne, Bentayga | |||
| CADILLAC | CTS, ATS, BLS | SRX, STS | Escalade | |
| CHEVROLET | Aveo,Spark | Evica, Lacetti, Rezzo, Niva, Cruze | TrailBlazer, Captiva, Corvette | Tahoe, Suburban |
| CHRYSLER | Neon | Sebring, Stratus, PT Cruiser | 300C, Grand Voyager, Pacifica | |
| CITROEN | C2, C3, C4, C6, Picasso, Berlingo, C5, DS-5 | C-crosser | ||
| FERRARI | California, 458, F12, 812, FF, GTC4 | |||
| FORD | Fusion, Fiesta, Ka | Focus, Kuga, Maverick, Escape, S-Max | Galaxy, Explorer, Mondeo | Raptor |
| HONDA | Jazz | Civic, HR-V, Accord, Prelude | CR-V, Legend, Element, Crosstour | Ridgeline |
| HUMMER | h3, h4 | |||
| HYUNDAI | Getz, I30, Atos, Solaris | Creta, Sonata, IX35, Matrix, Gran Deur | Santa Fe, IX55, Terracan,Tucson, Genesis | Eques, h2, Starex |
| INFINITI | Q30 | Q50 | QX70 | QX60, QX80, QX56 |
| JAGUAR | XJ, XF, F-type, F-pace | |||
| JEEP | Wrangler, Liberty | Compass, Cherokee | ||
| KIA | Rio, Picanto | Ceed,Optima, Sportage, Venga, Soul | Quoris, Sorento | Mohave |
| LADA | Granta, Priora | X-Ray | Нива | |
| LAMBORGHINI | Gallardo | Aventador, Urus | ||
| LAND ROVER | Freelander, Evoque, Discovery, Range Rover Sport | Defender, Range Rover Yoque | ||
| LEXUS | RX, NX, ES, GS, IS, CT | GX | LS, LX | |
| MASERATI | Ghibli, Levante | |||
| MAZDA | 2, 3, MX-5 | 5, 6, CX-5 | MPV, CX-7 | CX-9, BT-50 |
| MERCEDES-BENZ | A, B, C, SLK, CLK | E, GLK, GLA, SL, CLS | GLS, GLE, R, S, CL | V, AMG GT, G |
| MINI | Cooper | Countryman | ||
| MITSUBISHI | Colt, Lancer | Pajero Pinin, Space Star, ASX, Outlander | L-200, Outlander XL, Pajero Sport | |
| NISSAN | Note, Tiida, | Almera, Juke, Qashqai, 350Z, X-Trail | Murano, Teana, Navara, Pathfinder, | Micra, Patrol, GT-R |
| OPEL | Astra, Corsa | Zafira, Insignia, Omega, Vectra, Meriva | ||
| PEUGEOT | 107, 207, 308 | 407, 508, Partner | ||
| PORSCHE | Cayman, Boxster, 911, Macan | Cayenne, Panamera | ||
| RENAULT | Clio, Logan, Symbol | Kangoo, Duster, Fluence, Scenic, Megane, Laguna | Koleos | |
| ROLLS-ROYCE | Ghost, Wraith, Phantom | |||
| SKODA | Fabia, Ibiza | Octavia, Rapid, Superb, Roomster, Yeti | ||
| SUBARU | Forester, Legacy, Outback, Impreza XV | Tribeca | ||
| TOYOTA | Auris, Yaris | Avensis, Prius, Versa, GT86, Camry, Corolla | Venza, Highlander, Prado, FJ Cruiser | LC200, Tundra, Sequoya, Alphard |
| VOLVO | C30, S40 | S60, V50, V70 | XC60, XC70, XC90, S90, S80 | |
| VOLKSWAGEN | Scriocco, Beetle | Polo | Touran, Sharan, Passat, Golf plus, Jetta, Tiguan, Phaeton, Touareg | Multivan, Transporter |
Классификация авто с пробегом
01 июля 2022
У каждого транспортного средства своя индивидуальная жизнь, и состояние любого автомобиля определяется огромным количеством факторов. Для того, чтобы было проще ориентироваться, мы создали классификацию автомобилей с пробегом.
Для того, чтобы было проще ориентироваться, мы создали классификацию автомобилей с пробегом.
В зависимости от результатов диагностики автомобилю присваивается одна из категорий, характеризующая его техническое состояние. Допустимо присутствие не более двух пунктов из более низкой категории (не касается пунктов из последней категории).
Узнайте больше про автомобили с пробегом по телефону: +7 (4912) 460-760 или 701-930.
Мы находимся по адресу: г. Рязань, Московское шоссе, 12а.
Время работы: ежедневно с 09:00 до 21:00
Категория ADVICE (A)
- Возраст автомобиля (с даты первой регистрации): не более 5 лет
- Пробег: не более 75 000 км
- ТО: до ТО не менее 3 000 км, индикация ТО не горит
- Салон: элементы и детали интерьера салона не имеют повреждений и потертостей, посторонние запахи в салоне отсутствуют, не допускается наличие прожженных элементов интерьера салона
- ПТС: оригинал
- Количество владельцев: не более 2-х
- Кузов и диски: мелкие царапины и потертости ЛКП и колесных дисков не до “грунта”
- История: автомобиль не принимал участия в ДТП с нарушением геометрических параметров кузова/рамы
- Двигатель: работает в штатном режиме
- КПП: работает в штатном режиме
- Тормозная система: работает в штатном режиме
- Рулевое управление: работает в штатном режиме
- Электрооборудование: работает в штатном режиме
- Подвеска: работает в штатном режиме
Категория BASE (B)
- Возраст автомобиля (с даты первой регистрации): не более 10 лет
- Пробег: не более 150 000 км
- ТО: до ТО не менее 3 000 км, индикация ТО не горит
- Салон: на элементах интерьера допустимы царапины, потертости и механические повреждения, не требующие замену детали
- ПТС: оригинал/дубликат
- Кузов и диски: на ЛКП допустимы сколы, царапины, не устраняемые полировкой, незначительное число царапин до грунта, пластика или металла, незначительные повреждения кузовных деталей, следы поверхностной коррозии; отсутствуют визуально заметные крупные царапины, значительные кузовные повреждения, следы сквозной коррозии; вмятины, если они не превышают 10см в диаметре без повреждения лакокрасочного покрытия при условии не больше трех вмятин на автомобиле в целом
- История: автомобиль не принимал участия в ДТП с нарушением геометрических параметров кузова/рамы
- Двигатель: работает в штатном режиме
- КПП: работает в штатном режиме
- Тормозная система: работает в штатном режиме
- Рулевое управление: работает в штатном режиме
- Электрооборудование: работает в штатном режиме
- Подвеска: работает в штатном режиме
Категория COMPROMISE (C)
- Возраст автомобиля (с даты первой регистрации): не влияет
- Пробег: более 150 000 км
- Салон: допустимы повреждения обивки сидений, потолка, консоли, рычага коробки передач, обшивки дверей, следы, оставшиеся от пепла сигарет (прожоги)
- ПТС: оригинал/дубликат
- Кузов и диски: допустимы вмятины и повреждения колесных дисков, сквозная коррозия ЛКП, следы некачественного восстановительного ремонта, следы нарушения геометрии кузова
- История: автомобиль мог принимать участие в ДТП с нарушением геометрических параметров кузова / рамы
- Двигатель: работает в штатном режиме
- КПП: работает в штатном режиме
- Тормозная система: работает в штатном режиме (если иное не прописано в сертификате контроля)
- Рулевое управление: работает в штатном режиме
- Электрооборудование: работает в штатном режиме (если иное не прописано в сертификате контроля)
- Подвеска: работает в штатном режиме (если иное не прописано в сертификате контроля)
Категория «Z»
- Возраст автомобиля (с даты первой регистрации): не влияет
- Пробег подлинность пробега: не установлена
- Салон: допустимы повреждения, порезы обивки сидений, потолка, консоли, рычага коробки передач, обшивки дверей, следы, оставшиеся от пепла сигарет (прожоги), наличие большого количества или больших ярко выраженных пятен
- ПТС: оригинал/дубликат
- Кузов и диски: допустимы вмятины и повреждения колесных дисков, сквозная коррозия ЛКП, следы не качественного восстановительного ремонта, следы нарушения геометрии кузова
- История: автомобиль мог принимать участие в ДТП с нарушением геометрических параметров кузова/рамы
- Двигатель: может требовать ремонта
- КПП: может требовать ремонта
- Тормозная система: может требовать ремонта
- Рулевое управление: может требовать ремонта
- Подвеска: может требовать ремонта
Найти автомобиль
Вверх
Trade-in оценка
Связаться с дилером
Что такое классификация в машинном обучении?
Представьте, что вы открываете шкаф и видите, что все в нем перемешано. Вам будет очень трудно и долго брать то, что вам нужно. Если бы все было сгруппировано, было бы так просто. Это то, что делают алгоритмы классификации машинного обучения.
Вам будет очень трудно и долго брать то, что вам нужно. Если бы все было сгруппировано, было бы так просто. Это то, что делают алгоритмы классификации машинного обучения.
Что такое алгоритм классификации?
Алгоритм классификации, основанный на обучающих данных, представляет собой технику контролируемого обучения, используемую для категоризации новых наблюдений. При классификации программа использует предоставленный набор данных или наблюдения, чтобы научиться классифицировать новые наблюдения по различным классам или группам. Например, 0 или 1, красный или синий, да или нет, спам или не спам и т. д. Цели, метки или категории могут использоваться для описания классов. Алгоритм классификации использует помеченные входные данные, поскольку он представляет собой метод контролируемого обучения и включает в себя входную и выходную информацию. Дискретная выходная функция (y) передается входной переменной в процессе классификации (x).
Проще говоря, классификация — это тип распознавания образов, при котором алгоритмы классификации выполняются на обучающих данных для обнаружения того же шаблона в новых наборах данных.
Учащиеся в задачах классификации
Есть два типа учащихся.
Ленивые ученики
Сначала он сохраняет обучающий набор данных, а затем ожидает прибытия тестового набора данных. При использовании ленивого ученика классификация выполняется с использованием наиболее подходящих данных обучающего набора данных. Меньше времени тратится на обучение, но больше на прогнозы. Некоторые из примеров — рассуждения на основе прецедентов и алгоритм KNN.
Страстные ученики
Перед получением тестового набора данных активные учащиеся создают модель классификации, используя обучающий набор данных. Они тратят больше времени на изучение и меньше времени на предсказания. Некоторыми примерами являются ANN, наивный байесовский алгоритм и деревья решений.
Теперь давайте обсудим четыре типа задач классификации в машинном обучении.
4 типа задач классификации в машинном обучении
Прежде чем углубиться в четыре типа задач классификации в машинном обучении, давайте сначала обсудим прогнозное моделирование классификации.
Прогнозное моделирование классификации
Проблема классификации в машинном обучении — это проблема, в которой метка класса ожидается для конкретного примера входных данных.
Проблемы с категоризацией включают следующее:
- Приведите пример и укажите, спам это или нет.
- Идентифицировать рукописный символ как один из распознаваемых символов.
- Определите, следует ли помечать текущее поведение пользователя как отток.
Набор обучающих данных с многочисленными примерами входных и выходных данных необходим для классификации с точки зрения моделирования.
Модель определит оптимальный способ сопоставления выборок входных данных с определенными метками классов с использованием обучающего набора данных. Таким образом, обучающий набор данных должен содержать большое количество образцов каждой метки класса и должным образом представлять проблему.
При предоставлении меток классов для алгоритма моделирования строковые значения, такие как «спам» или «не спам», должны быть сначала преобразованы в числовые значения. Часто используемое кодирование метки присваивает каждой метке класса отдельное целое число, например, «спам» = 0, «нет спама» = 1,9.0003
Часто используемое кодирование метки присваивает каждой метке класса отдельное целое число, например, «спам» = 0, «нет спама» = 1,9.0003
Существует множество разновидностей алгоритмов классификации в задачах моделирования, включая прогностическое моделирование и классификацию.
Обычно рекомендуется, чтобы практикующий специалист провел контролируемые тесты, чтобы определить, какой алгоритм и конфигурация алгоритма обеспечивают наибольшую производительность для определенной задачи классификации, поскольку нет надежной теории о том, как сопоставлять алгоритмы с типами задач.
На основе их результатов оцениваются алгоритмы прогнозного моделирования классификации. Общей статистикой для оценки производительности модели на основе спроецированных меток классов является точность классификации. Хотя точность классификации не идеальна, она является разумным началом для многих задач по классификации.
Некоторые задачи могут требовать предсказания вероятности принадлежности к классу для каждого примера, а не меток классов. Это добавляет больше неопределенности прогнозу, который впоследствии может интерпретировать пользователь или приложение. Кривая ROC — популярная диагностика для оценки ожидаемых вероятностей.
Это добавляет больше неопределенности прогнозу, который впоследствии может интерпретировать пользователь или приложение. Кривая ROC — популярная диагностика для оценки ожидаемых вероятностей.
В машинном обучении существует четыре различных типа задач классификации, и они следующие:
- Бинарная классификация
- Многоклассовая классификация
- Многоуровневая классификация
- Несбалансированная классификация
Теперь давайте подробно рассмотрим каждый из них.
Бинарная классификация
Задания классификации только с двумя метками класса называются бинарной классификацией.
Примеры включают —
- Прогноз конверсии (купить или нет).
- Прогноз оттока (отток или нет).
- Обнаружение нежелательной почты (спам или нет).
Для задач бинарной классификации часто требуется два класса, один из которых представляет нормальное состояние, а другой — аберрантное состояние.
Например, нормальное состояние — «не спам», а ненормальное — «спам». Другой пример: задача, связанная с медицинским тестом, имеет нормальное состояние «рак не выявлен» и ненормальное состояние «рак обнаружен».
Метка класса 0 присваивается классу в нормальном состоянии, тогда как метка класса 1 присваивается классу в ненормальном состоянии.
Модель, которая прогнозирует распределение вероятностей Бернулли для каждого случая, часто используется для представления задачи бинарной классификации.
Дискретное распределение вероятностей, известное как распределение Бернулли, имеет дело с ситуацией, когда событие имеет двоичный результат либо 0, либо 1. С точки зрения классификации это означает, что модель прогнозирует вероятность того, что пример попадет в класс 1, или ненормальное состояние.
Ниже приведены хорошо известные алгоритмы бинарной классификации:
- Логистическая регрессия
- Машины опорных векторов
- Простой Байес
- Деревья решений
Некоторые алгоритмы, такие как машины опорных векторов и логистическая регрессия, были созданы специально для бинарной классификации и по умолчанию не поддерживают более двух классов.
Давайте теперь обсудим многоклассовую классификацию.
Многоклассовая классификация
Мультиклассовые метки используются в задачах классификации, называемых мультиклассовой классификацией.
Примеры включают —
- Категоризация лиц.
- Классификация видов растений.
- Распознавание символов с помощью оптики.
Мультиклассовая классификация не имеет представления о нормальных и ненормальных исходах, в отличие от бинарной классификации. Вместо этого экземпляры группируются в один из нескольких хорошо известных классов.
В некоторых случаях количество меток классов может быть довольно большим. Например, в системе распознавания лиц модель может предсказать, что снимок принадлежит одному из тысяч или десятков тысяч лиц.
Модели перевода текста и другие задачи, связанные с предсказанием слов, можно отнести к частному случаю многоклассовой классификации. Каждое слово в последовательности слов, которые необходимо предсказать, требует многоклассовой классификации, где размер словаря определяет количество возможных классов, которые могут быть предсказаны, и может варьироваться от десятков тысяч до сотен тысяч слов.
Каждое слово в последовательности слов, которые необходимо предсказать, требует многоклассовой классификации, где размер словаря определяет количество возможных классов, которые могут быть предсказаны, и может варьироваться от десятков тысяч до сотен тысяч слов.
Задачи мультиклассовой классификации часто моделируются с использованием модели, которая прогнозирует распределение вероятности Мультинулли для каждого примера.
Событие, имеющее категориальный исход, например K из 1, 2, 3,…, K, покрывается распределением Мультинулли, которое представляет собой дискретное распределение вероятностей. С точки зрения классификации это означает, что модель прогнозирует вероятность того, что данный пример будет принадлежать к определенной метке класса.
Для многоклассовой классификации применимы многие методы бинарной классификации.
Для многоклассовой классификации можно использовать следующие известные алгоритмы:
- Прогрессивное усиление
- Деревья выбора
- Ближайшие K соседей
- Неровный лес
- Простой Байес
Многоклассовые задачи могут быть решены с помощью алгоритмов, созданных для бинарной классификации.
Для этого используется метод, известный как «один против остальных» или «одна модель для каждой пары классов», который включает сопоставление нескольких моделей бинарной классификации с каждым классом со всеми другими классами (называемыми против одного).
- Один против одного: для каждой пары классов подберите одну модель бинарной классификации.
Следующие алгоритмы двоичной классификации могут применять эти методы многоклассовой классификации:
- One-vs-Rest: Подберите единую модель бинарной классификации для каждого класса по сравнению со всеми другими классами.
Следующие алгоритмы двоичной классификации могут применять эти методы многоклассовой классификации:
- Опорный вектор Машина
- Логистическая регрессия
Давайте теперь узнаем о классификации с несколькими метками.
Многоуровневая классификация
Проблемы классификации с несколькими метками — это задачи, в которых есть две или более метки класса и которые позволяют прогнозировать одну или несколько меток класса для каждого примера.
Подумайте о примере классификации фотографий. Здесь модель может предсказать наличие на фотографии многих известных вещей, таких как «человек», «яблоко», «велосипед» и т. д. На конкретной фотографии может быть несколько объектов в сцене.
Это сильно отличается от многоклассовой классификации и бинарной классификации, которые предполагают наличие одной метки класса для каждого случая.
Проблемы классификации с несколькими метками часто моделируются с использованием модели, которая прогнозирует множество результатов, причем каждый результат прогнозируется как распределение вероятностей Бернулли. По сути, этот подход предсказывает несколько бинарных классификаций для каждого примера.
Невозможно напрямую применить методы классификации с несколькими метками, используемые для многоклассовой или бинарной классификации. Так называемые версии алгоритмов с несколькими метками, которые являются специализированными версиями обычных алгоритмов классификации, включают:
- Multi-label Gradient Boosting
- Случайные леса с несколькими метками
- Деревья решений с несколькими метками
Другая стратегия заключается в прогнозировании меток классов с использованием другого алгоритма классификации.
Теперь мы подробно рассмотрим задачу несбалансированной классификации.
Несбалансированная классификация
Термин «несбалансированная классификация» описывает классификационные задания, в которых распределение примеров внутри каждого класса неодинаково.
Большинство экземпляров обучающего набора данных принадлежат к нормальному классу, а меньшинство принадлежит к аномальному классу, что делает несбалансированные задачи классификации в целом задачами бинарной классификации.
Примеры включают —
- Клинические диагностические процедуры
- Обнаружение выбросов
- Расследование мошенничества
Хотя им могут потребоваться уникальные методы, эти проблемы моделируются как задания бинарной классификации.
Путем избыточной выборки класса меньшинства или недостаточной выборки класса большинства можно использовать специальные стратегии для изменения состава выборки в обучающем наборе данных.
Примеры включают —
- SMOTE Передискретизация
- Случайная неполная выборка
Можно использовать специализированные методы моделирования, такие как экономичные алгоритмы машинного обучения, которые уделяют больше внимания классу меньшинств при подгонке модели к обучающему набору данных.
Примеры включают:
- Недорогие машины опорных векторов
- Чувствительные к стоимости деревья решений
- Логистическая регрессия с учетом затрат
Поскольку сообщение о точности классификации может быть обманчивым, могут потребоваться альтернативные индикаторы эффективности.
Примеры включают —
- F-мера
- Отзыв
- Точность
Теперь мы обсудим типы алгоритмов классификации машинного обучения.
Типы алгоритмов классификации
Вы можете применять множество различных методов классификации на основе набора данных, с которым вы работаете. Это так, потому что изучение классификации в статистике обширно. Ниже перечислены пять лучших алгоритмов машинного обучения.
Это так, потому что изучение классификации в статистике обширно. Ниже перечислены пять лучших алгоритмов машинного обучения.
1. Логистическая регрессия
Это метод классификации обучения с учителем, который прогнозирует вероятность целевой переменной. Выбор будет только между двумя классами. Данные могут быть закодированы как единица или да, что означает успех, или как 0 или нет, что означает неудачу. Зависимая переменная может быть предсказана наиболее эффективно с помощью логистической регрессии. Когда прогноз является категоричным, например, истинным или ложным, да или нет, или 0 или 1, вы можете его использовать. Чтобы определить, является ли электронное письмо спамом, можно использовать метод логистической регрессии.
2. Наивные прощания
Наивный байесовский метод определяет, попадает ли точка данных в определенную категорию. Его можно использовать для классификации фраз или слов в текстовом анализе как подпадающих под заранее определенную классификацию, так и не подпадающих под нее.
Текст | Тег |
«Отличная игра» | Спорт |
«Выборы окончены» | Не спортивный |
«Какой отличный результат» | Спорт |
«Чистая и незабываемая игра» | Спорт |
«Победитель конкурса правописания стал сюрпризом» | Не спортивный |
3. K-ближайшие соседи
Вычисляет вероятность того, что точка данных присоединится к группам, в зависимости от того, частью какой группы являются ближайшие к ней точки данных. При использовании k-NN для классификации вы определяете, как классифицировать данные в соответствии с ближайшим соседом.
4. Дерево решений
Дерево решений является примером контролируемого обучения. Хотя он может решать проблемы регрессии и классификации, он превосходен в задачах классификации. Подобно блок-схеме, он делит точки данных на две похожие группы одновременно, начиная со «ствола дерева» и переходя через «ветви» и «листья», пока категории не станут более тесно связаны друг с другом.
Подобно блок-схеме, он делит точки данных на две похожие группы одновременно, начиная со «ствола дерева» и переходя через «ветви» и «листья», пока категории не станут более тесно связаны друг с другом.
5. Алгоритм случайного леса
Алгоритм случайного леса является расширением алгоритма дерева решений, в котором вы сначала создаете несколько деревьев решений, используя обучающие данные, а затем вписываете свои новые данные в одно из созданных «деревьев» в качестве «случайного леса». Он усредняет данные, чтобы связать их с данными ближайшего дерева на основе шкалы данных. Эти модели отлично подходят для решения проблемы дерева решений, связанной с ненужным размещением точек данных внутри категории.
6. Машина опорных векторов
Метод опорных векторов — это популярный метод контролируемого машинного обучения для задач классификации и регрессии. Он выходит за рамки предсказания X/Y, используя алгоритмы для классификации и обучения данных в соответствии с полярностью.
Типы алгоритмов классификации машинного обучения
1. Подход к обучению под наблюдением
Подход к обучению с учителем явно обучает алгоритмы под пристальным наблюдением человека. И входные, и выходные данные сначала предоставляются алгоритму. Затем алгоритм разрабатывает правила, которые сопоставляют входные данные с выходными. Процедура обучения повторяется, как только достигается наивысший уровень производительности.
Два типа подходов к контролируемому обучению:
- Регрессия
- Классификация
2. Обучение без учителя
Этот подход применяется для изучения внутренней структуры данных и извлечения из нее полезной информации. Этот метод ищет идеи, которые могут дать лучшие результаты, ища закономерности и идеи в неразмеченных данных.
Существует два типа обучения без учителя:
- Кластеризация
- Уменьшение размерности
3.
 Обучение под наблюдением
Обучение под наблюдениемПолууправляемое обучение находится где-то между обучением без учителя и обучением с учителем. Он сочетает в себе наиболее важные аспекты обоих миров, чтобы обеспечить уникальный набор алгоритмов.
4. Обучение с подкреплением
Целью обучения с подкреплением является создание автономных самосовершенствующихся алгоритмов. Цель алгоритма — самосовершенствоваться посредством непрерывного цикла проб и ошибок, основанного на взаимодействиях и комбинациях между поступающими и помеченными данными.
Классификация моделей
- Наивный Байес: Наивный Байес — это алгоритм классификации, который предполагает, что предикторы в наборе данных независимы. Это означает, что он предполагает, что функции не связаны друг с другом. Например, если дать банан, классификатор увидит, что плод желтого цвета, продолговатой формы, длинный и заостренный. Все эти признаки независимо влияют на вероятность того, что это банан, и не зависят друг от друга.
 Наивный Байес основан на теореме Байеса, которая задается как:
Наивный Байес основан на теореме Байеса, которая задается как:
Рисунок 3: Теорема Байеса
Где :
P(A | B) = как часто происходит, учитывая, что B происходит
P(A) = вероятность наступления события A
P(B) = вероятность того, что B произойдет
P(B | A) = как часто происходит B при условии, что происходит A
- Деревья решений. Дерево решений — это алгоритм, который используется для визуального представления процесса принятия решений. Дерево решений можно составить, задав вопрос «да/нет» и разделив ответ, чтобы получить другое решение. Вопрос находится в узле, и он размещает полученные решения ниже, на листьях. Дерево, изображенное ниже, используется, чтобы решить, можем ли мы играть в теннис.
Рисунок 4. Дерево решений
На приведенном выше рисунке, в зависимости от погодных условий, влажности и ветра, мы можем систематически решать, играть нам в теннис или нет. В деревьях решений все ложные утверждения лежат слева от дерева, а истинные утверждения ответвляются вправо. Зная это, мы можем построить дерево, в узлах которого будут признаки, а в листьях — результирующие классы.
В деревьях решений все ложные утверждения лежат слева от дерева, а истинные утверждения ответвляются вправо. Зная это, мы можем построить дерево, в узлах которого будут признаки, а в листьях — результирующие классы.
- K-ближайшие соседи: K-ближайшие соседи — это алгоритм классификации и прогнозирования, который используется для разделения данных на классы на основе расстояния между точками данных. K-ближайший сосед предполагает, что точки данных, которые находятся близко друг к другу, должны быть похожими, и, следовательно, точка данных, подлежащая классификации, будет сгруппирована с ближайшим кластером.
Рисунок 5: Данные, подлежащие классификации
Рисунок 6: Классификация с использованием K-ближайших соседей
Оценка модели классификации
После того, как наша модель завершена, мы должны оценить ее производительность, чтобы определить, является ли она регрессионной или классификационной моделью. Итак, у нас есть следующие варианты оценки модели классификации:
Итак, у нас есть следующие варианты оценки модели классификации:
1. Матрица путаницы
- Матрица путаницы описывает производительность модели и дает нам матрицу или таблицу в качестве выходных данных.
- Матрица ошибок — это другое название.
- Матрица состоит из результатов прогнозов в сжатом виде вместе с общим количеством правильных и неправильных предположений.
Матрица приведена в следующей таблице:
Фактическое положительное значение | Фактическое отрицательное значение | |
Прогнозируемый положительный результат | Истинно положительный | Ложное срабатывание |
Прогнозируемый отрицательный результат | Ложноотрицательный результат | Истинно отрицательный результат |
Точность = (TP+TN)/Общая численность населения
2.
 Потеря журнала или кросс-энтропийная потеря
Потеря журнала или кросс-энтропийная потеря- Он используется для оценки производительности классификатора, а выход представляет собой значение вероятности от 1 до 0.
- Успешная модель двоичной классификации должна иметь значение потери журнала, близкое к 0.
- Если ожидаемое значение отличается от фактического значения, увеличивается значение потери журнала.
- Чем ниже логарифмическая потеря, тем выше точность модели.
Кросс-энтропия для бинарной классификации может быть рассчитана как:
(ylog(p)+(1?y)log(1?p))
Где p = прогнозируемый выход, y = фактический выход.
3. Кривая AUC-ROC
- AUC — это область под кривой, а ROC — это кривая рабочих характеристик приемника.
- Это график, отображающий производительность модели классификации при различных пороговых значениях.
- Кривая AUC-ROC используется, чтобы показать, насколько хорошо работает мультиклассовая модель классификации.

- TPR и FPR используются для построения ROC-кривой с истинной положительной частотой (TPR) на оси Y и FPR (ложноположительной частотой) на оси X.
Теперь давайте обсудим варианты использования алгоритмов классификации.
Варианты использования алгоритмов классификации
Существует много приложений для алгоритмов классификации. Вот некоторые из них
- Распознавание речи
- Обнаружение спама
- Классификация наркотиков
- Идентификация клеток раковой опухоли
- Биометрическая аутентификация и т. д.
Оценка классификатора
Оценка для проверки точности и эффективности классификатора является наиболее важным шагом после его завершения. Мы можем оценить классификатор различными способами. Давайте рассмотрим эти методы, которые изложены ниже, начиная с перекрестной проверки.
Перекрестная проверка
Самая заметная проблема с большинством моделей машинного обучения — чрезмерная подгонка. Можно проверить переоснащение модели с помощью перекрестной проверки K-кратности.
Можно проверить переоснащение модели с помощью перекрестной проверки K-кратности.
При использовании этого метода набор данных случайным образом делится на k одинаковых по размеру взаимоисключающих подмножеств. Один сохраняется для тестирования, а другие используются для обучения модели. Для каждой из k складок выполняется та же процедура.
Метод удержания
Этот подход чаще всего используется для оценки классификаторов. Согласно этому методу данный набор данных разбивается на тестовый набор и набор поездов, каждый из которых включает 20% и 80% от общего объема данных.
Невидимый тестовый набор используется для оценки способности данных прогнозировать после того, как они были обучены с использованием обучающего набора.
ROC-кривая
Для визуального сравнения моделей классификации используется кривая ROC, также известная как рабочие характеристики приемника. Он иллюстрирует корреляцию между процентом ложноположительных результатов и процентом истинно положительных результатов. Точность модели определяется площадью под ROC-кривой.
Точность модели определяется площадью под ROC-кривой.
Смещение и отклонение
Смещение — это разница между нашими фактическими и прогнозируемыми значениями. Смещение — это простые предположения, которые наша модель делает о наших данных, чтобы иметь возможность прогнозировать новые данные. Это напрямую соответствует закономерностям, обнаруженным в наших данных. Когда смещение высокое, предположения, сделанные нашей моделью, слишком базовые, модель не может отразить важные особенности наших данных, это называется недообучением.
Рис. 7. Смещение
Мы можем определить дисперсию как чувствительность модели к колебаниям данных. Наша модель может учиться на шуме. Это заставит нашу модель считать тривиальные функции важными. Когда дисперсия высока, наша модель захватит все характеристики предоставленных ей данных, настроится на данные и очень хорошо предскажет их, но новые данные могут не иметь точно таких же характеристик, и модель не будет в состоянии предсказать на нем очень хорошо. Мы называем это переоснащением.
Мы называем это переоснащением.
Рисунок 8. Пример отклонения
Точность и отзыв
Точность используется для расчета способности модели правильно классифицировать значения. Он определяется путем деления количества правильно классифицированных точек данных на общее количество классифицированных точек данных для этой метки класса.
Где:
TP = True Positives, когда наша модель правильно классифицирует точку данных по классу, к которому она принадлежит.
FP = ложные срабатывания, когда модель ошибочно классифицирует точку данных.
Recall используется для расчета способности режима прогнозировать положительные значения. Но «Как часто модель предсказывает правильные положительные значения?». Это рассчитывается по соотношению истинных положительных значений и общего количества фактических положительных значений.
Теперь давайте посмотрим на выбор алгоритма.
Выбор алгоритма
В дополнение к стратегии, описанной выше, мы можем применить процедуры, перечисленные ниже, чтобы выбрать оптимальный алгоритм для модели.
- Прочитать информацию.
- На основе наших независимых и зависимых функций и создания зависимых и независимых наборов данных.
- Создайте наборы данных для обучения и тестирования.
- Используйте множество алгоритмов для обучения модели, включая SVM, дерево решений, KNN и т. д.
- Рассмотрим классификатор.
- Выберите наиболее точный классификатор.
Точность — это лучший способ сделать вашу модель эффективной, даже если выбор оптимального алгоритма для вашей модели может занять больше времени, чем необходимо.
Наши учащиеся также спрашивали
1. Что такое алгоритм классификации на примере?
Классификация включает прогнозирование метки класса для конкретного примера входных данных. Например, он может определить, является ли код спамом. Он может классифицировать почерк, если он состоит из одного из известных символов.
2. Каков наилучший алгоритм классификации?
По сравнению с другими алгоритмами классификации, такими как логистическая регрессия, машины опорных векторов и регрессия решений, алгоритм наивного байесовского классификатора дает лучшие результаты.
3. Какой самый простой алгоритм классификации?
Одним из самых простых методов классификации является kNN.
4. Классификатор или алгоритм в машинном обучении?
Метод или набор рекомендаций, которые компьютеры используют для категоризации данных, известен как классификатор. Когда дело доходит до модели классификации, это результат классификаторов ML. Классификатор используется для обучения модели, которая затем классифицирует ваши данные.
5. Что такое классификация и типы?
Классификация — это категория или подразделение в системе, которая классифицирует или организует объекты по группам или типам. Вы можете столкнуться со следующими четырьмя категориями задач классификации: бинарная, многоклассовая, многоуровневая и несбалансированная классификация.
6. В чем разница между классификацией и кластеризацией?
Цель кластеризации состоит в том, чтобы сгруппировать схожие типы элементов, принимая во внимание наиболее удовлетворяющие критерии, согласно которым никакие два элемента в одной и той же группе не должны быть сопоставимы. Это отличается от классификации, целью которой является прогнозирование целевого класса.
Ускорьте свою карьеру в области искусственного интеллекта и машинного обучения с помощью курса по искусственному интеллекту и машинному обучению, организованного Университетом Пердью в сотрудничестве с IBM.
Классификация машинного обучения | Алгоритмы классификации
Стать сертифицированным специалистом
Классификация в машинном обучении и статистике — это контролируемый подход к обучению, при котором компьютерная программа учится на данных, предоставленных ей, и делает новые наблюдения или классификации. В этой статье мы подробно узнаем о классификации в машинном обучении. Более того, если вы хотите выйти за рамки этой статьи и получить практический опыт машинного обучения под руководством экспертов, обязательно посетите сертификацию машинного обучения от Edureka!
Более того, если вы хотите выйти за рамки этой статьи и получить практический опыт машинного обучения под руководством экспертов, обязательно посетите сертификацию машинного обучения от Edureka!
Полный курс машинного обучения — изучение машинного обучения, 10 часов | Учебник по машинному обучению | Edureka
Курс машинного обучения позволяет освоить применение ИИ под руководством экспертов. Он включает в себя различные алгоритмы с приложениями.
В этом блоге рассматриваются следующие темы:
- Что такое классификация в машинном обучении?
- Терминология классификации в машинном обучении
- Алгоритмы классификации
- Логистическая регрессия
- Наивный байесовский метод
- Стохастический градиентный спуск
- K-ближайшие соседи
- Дерево решений
- Случайный лес
- Машина опорных векторов
- Оценка классификатора
- Алгоритм Выбор
- Пример использования — Классификация цифр MNIST
Классификация — это процесс классификации заданного набора данных по классам.
 Он может выполняться как со структурированными, так и с неструктурированными данными. Процесс начинается с прогнозирования класса заданных точек данных. Классы часто называют целевыми, метками или категориями.
Он может выполняться как со структурированными, так и с неструктурированными данными. Процесс начинается с прогнозирования класса заданных точек данных. Классы часто называют целевыми, метками или категориями.Классификационное прогностическое моделирование представляет собой задачу аппроксимации функции отображения от входных переменных к дискретным выходным переменным. Основная цель — определить, к какому классу/категории попадут новые данные.
Попробуем понять это на простом примере.
Обнаружение болезни сердца можно определить как проблему классификации, это бинарная классификация, поскольку может быть только два класса, т. е. есть болезнь сердца или нет болезни сердца. В этом случае классификатору нужны обучающие данные, чтобы понять, как данные входные переменные связаны с классом. И как только классификатор будет точно обучен, его можно будет использовать для определения наличия или отсутствия болезни сердца у конкретного пациента.

Так как классификация является типом обучения под наблюдением, даже цели также снабжены входными данными. Давайте познакомимся с классификацией в терминологии машинного обучения.
Терминология классификации в машинном обученииКлассификатор — это алгоритм, который используется для сопоставления входных данных с определенной категорией.
Модель классификации — модель прогнозирует или делает вывод на основе входных данных, предоставленных для обучения, она будет прогнозировать класс или категорию данных.
Признак – Признак – это отдельное измеримое свойство наблюдаемого явления.
Двоичная классификация — это тип классификации с двумя результатами, например, либо истина, либо ложь.
Многоклассовая классификация – Классификация с более чем двумя классами, в многоклассовой классификации каждому образцу назначается одна и только одна метка или цель.

Классификация с несколькими метками — это тип классификации, в котором каждому образцу назначается набор меток или целей.
Инициализация – Назначение классификатора для использования в
Обучение классификатора обучение поезда X и метки поезда y.
Предсказать цель — Для немаркированного наблюдения X метод прогнозирования (X) возвращает прогнозируемую метку y.
Оценка – это в основном означает оценку модели, т.е. отчет о классификации, показатель точности и т. д.
Типы учащихся в классификации Ленивые учащиеся просто запоминают обучающие данные и дождитесь появления тестовых данных. Классификация выполняется с использованием наиболее связанных данных в сохраненных обучающих данных. У них больше времени на прогнозирование по сравнению с нетерпеливыми учениками. Например – k-ближайший сосед, рассуждение по прецедентам.

Нетерпеливые учащиеся — Нетерпеливые учащиеся строят модель классификации на основе данных обучения, прежде чем получать данные для прогнозов. Он должен быть в состоянии принять единую гипотезу, которая будет работать для всего пространства. За счет этого они занимают много времени на обучение и меньше времени на прогноз. Например, дерево решений, наивный байесовский алгоритм, искусственные нейронные сети.
Постройте карьеру в области искусственного интеллекта с нашим дипломом последипломного образования на курсах AI ML.
Алгоритмы классификации В машинном обучении классификация — это концепция контролируемого обучения, которая в основном распределяет набор данных по классам. Наиболее распространенными проблемами классификации являются — распознавание речи, распознавание лиц, распознавание рукописного текста, классификация документов и т. д. Это может быть как проблема бинарной классификации, так и задача с несколькими классами. Существует множество алгоритмов машинного обучения для классификации в машинном обучении. Давайте посмотрим на эти алгоритмы классификации в машинном обучении.
Существует множество алгоритмов машинного обучения для классификации в машинном обучении. Давайте посмотрим на эти алгоритмы классификации в машинном обучении.
Это алгоритм классификации в машинном обучении, который использует одну или несколько независимых переменных для определения результата. Результат измеряется дихотомической переменной, означающей , что у него будет только два возможных результата .
Цель логистической регрессии — найти наиболее подходящую связь между зависимой переменной и набором независимых переменных. Он лучше, чем другие алгоритмы бинарной классификации, такие как ближайший сосед, поскольку количественно объясняет факторы, приводящие к классификации.
Преимущества и недостатки
Логистическая регрессия специально предназначена для классификации, она полезна для понимания того, как набор независимых переменных влияет на результат зависимой переменной.
Основным недостатком алгоритма логистической регрессии является то, что он работает только тогда, когда прогнозируемая переменная является двоичной, он предполагает, что данные не содержат пропущенных значений, и предполагает, что предикторы независимы друг от друга.
Варианты использования
Узнайте больше о логистической регрессии с помощью Python здесь.
Наивный байесовский классификатор
Это алгоритм классификации, основанный на теореме Байеса , которая предполагает независимость предикторов. Проще говоря, наивный байесовский классификатор предполагает, что наличие определенной функции в классе не связано с наличием какой-либо другой функции.
Даже если признаки зависят друг от друга, все эти свойства влияют на вероятность независимо друг от друга. Наивную байесовскую модель легко построить, и она особенно полезна для сравнительно больших наборов данных. Известно, что даже при упрощенном подходе Наивный Байес превосходит большинство методов классификации в машинном обучении. Ниже приводится теорема Байеса для реализации наивной теоремы Байеса.
Ниже приводится теорема Байеса для реализации наивной теоремы Байеса.
Преимущества и недостатки
Наивному байесовскому классификатору требуется небольшой объем обучающих данных для оценки необходимых параметров для получения результатов. Они чрезвычайно быстры по своей природе по сравнению с другими классификаторами.
Единственным недостатком является то, что они известны своей плохой оценкой.
Варианты использования
Узнайте больше о наивном байесовском классификаторе здесь.
Стохастический градиентный спускЭто очень эффективный и простой подход к подбору линейных моделей. Стохастический градиентный спуск особенно полезен, когда выборочные данные находятся в большом количестве . Он поддерживает различные функции потерь и штрафы за классификацию.
Стохастический градиентный спуск относится к вычислению производной от каждого экземпляра обучающих данных и немедленному вычислению обновления.
Преимущества и недостатки
Единственным преимуществом является простота реализации и эффективность, тогда как основным недостатком стохастического градиентного спуска является то, что он требует ряда гиперпараметров и чувствителен к масштабированию признаков.
Варианты использования
K-ближайший соседЭто алгоритм ленивого обучения, в котором хранит все экземпляры, соответствующие обучающим данным, в n-мерном пространстве . Это алгоритм ленивого обучения , поскольку он не фокусируется на построении общей внутренней модели, а работает на хранении экземпляров обучающих данных.
Классификация вычисляется простым большинством голосов k ближайших соседей каждой точки. Он контролируется и берет кучу помеченных точек и использует их для обозначения других точек. Чтобы пометить новую точку, он просматривает помеченные точки, ближайшие к этой новой точке, также известные как ее ближайшие соседи. Эти соседи голосуют, поэтому любая метка, которую имеет большинство соседей, является меткой для новой точки. «k» — это количество проверенных соседей.
Эти соседи голосуют, поэтому любая метка, которую имеет большинство соседей, является меткой для новой точки. «k» — это количество проверенных соседей.
Ознакомьтесь с нашим сертификационным курсом по машинному обучению в ведущих городах
Преимущества и недостатки
Этот алгоритм довольно прост в реализации и устойчив к зашумленным обучающим данным. Даже если тренировочные данные большие, они достаточно эффективны. Единственный недостаток алгоритма KNN заключается в том, что нет необходимости определять значение K, а стоимость вычислений довольно высока по сравнению с другими алгоритмами.
Примеры использования
Узнайте больше об алгоритме K ближайших соседей здесь
Дерево решений Алгоритм дерева решений строит модель классификации в форме древовидной структуры . Он использует правила «если-то», которые в равной степени являются исчерпывающими и взаимоисключающими в классификации. Процесс продолжается с разбивкой данных на более мелкие структуры и, в конечном счете, связыванием их с возрастающим деревом решений. Окончательная структура выглядит как дерево с узлами и листьями. правила изучаются последовательно с использованием обучающих данных по одному. Каждый раз, когда правило изучается, кортежи, охватывающие правила, удаляются. Процесс продолжается на тренировочном наборе до тех пор, пока не будет достигнута точка завершения.
Процесс продолжается с разбивкой данных на более мелкие структуры и, в конечном счете, связыванием их с возрастающим деревом решений. Окончательная структура выглядит как дерево с узлами и листьями. правила изучаются последовательно с использованием обучающих данных по одному. Каждый раз, когда правило изучается, кортежи, охватывающие правила, удаляются. Процесс продолжается на тренировочном наборе до тех пор, пока не будет достигнута точка завершения.
Дерево строится по принципу «разделяй и властвуй» сверху вниз. Узел решения будет иметь две или более ветвей, а лист представляет собой классификацию или решение. Самый верхний узел в дереве решений, который соответствует лучшему предсказателю, называется корневым узлом, и лучшее в дереве решений то, что оно может обрабатывать как категориальные, так и числовые данные.
Преимущества и недостатки
Преимуществом дерева решений является простота понимания и визуализации, а также требуется очень небольшая подготовка данных. Недостаток, который следует за деревом решений, заключается в том, что оно может создавать сложные деревья, которые могут эффективно классифицировать. Они могут быть весьма нестабильными, потому что даже простое изменение данных может нарушить всю структуру дерева решений.
Недостаток, который следует за деревом решений, заключается в том, что оно может создавать сложные деревья, которые могут эффективно классифицировать. Они могут быть весьма нестабильными, потому что даже простое изменение данных может нарушить всю структуру дерева решений.
Варианты использования
Узнайте больше об алгоритме дерева решений здесь
Случайный лес
Случайные деревья решений или случайный лес — это ансамблевый метод обучения для классификации, регрессии и т. д. Он работает путем построения множества деревьев решений во время обучения и выводит класс, который является режимом. классов или классификации или среднего предсказания (регрессии) отдельных деревьев.
Случайный лес — это метаоценка, которая сопоставляет несколько деревьев в различных подвыборках наборов данных, а затем использует среднее значение для повышения точности предиктивного характера модели. Размер подвыборки всегда такой же, как у исходного входного размера, но выборки часто составляются с заменами.
Размер подвыборки всегда такой же, как у исходного входного размера, но выборки часто составляются с заменами.
Преимущества и недостатки
Преимущество случайного леса заключается в том, что он более точен, чем деревья решений, благодаря уменьшению переобучения. Единственным недостатком классификаторов случайного леса является то, что они довольно сложны в реализации и довольно медленны в прогнозировании в реальном времени.
Сценарии использования
Промышленные приложения, такие как определение того, относится ли заявитель к кредиту к группе высокого или низкого риска
Для прогнозирования выхода из строя механических частей автомобильных двигателей
для прогнозирования оценок в социальных сетях
для оценки производительности
Узнайте больше об алгоритме Random Forest здесь.
Искусственные нейронные сети
Нейронная сеть состоит из нейронов, которые расположены в слоях , они принимают некоторый входной вектор и преобразуют его в выходной. В этом процессе каждый нейрон принимает входные данные и применяет к нему функцию, которая часто является нелинейной функцией, а затем передает выходные данные следующему слою.
В этом процессе каждый нейрон принимает входные данные и применяет к нему функцию, которая часто является нелинейной функцией, а затем передает выходные данные следующему слою.
В целом предполагается, что сеть имеет прямую связь, что означает, что единица или нейрон передает выходные данные следующему слою, но никакая обратная связь с предыдущим слоем не задействована.
Взвешивания применяются к сигналам, проходящим от одного слоя к другому, и это взвешивания, которые настраиваются на этапе обучения для адаптации нейронной сети к любой постановке задачи.
Преимущества и недостатки
Он обладает высокой устойчивостью к зашумленным данным и способен классифицировать необученные шаблоны. Он лучше работает с непрерывными входными и выходными данными. Недостатком искусственных нейронных сетей является то, что они плохо интерпретируются по сравнению с другими моделями.
Варианты использования
Анализ почерка
Раскрашивание черно-белых изображений
Компьютерное зрение
Узнайте больше об искусственных нейронных сетях здесь
Машина опорных векторов
Машина опорных векторов — это классификатор, который представляет тренировочные данные в виде точек в пространстве , разделенных на категории максимально широким зазором.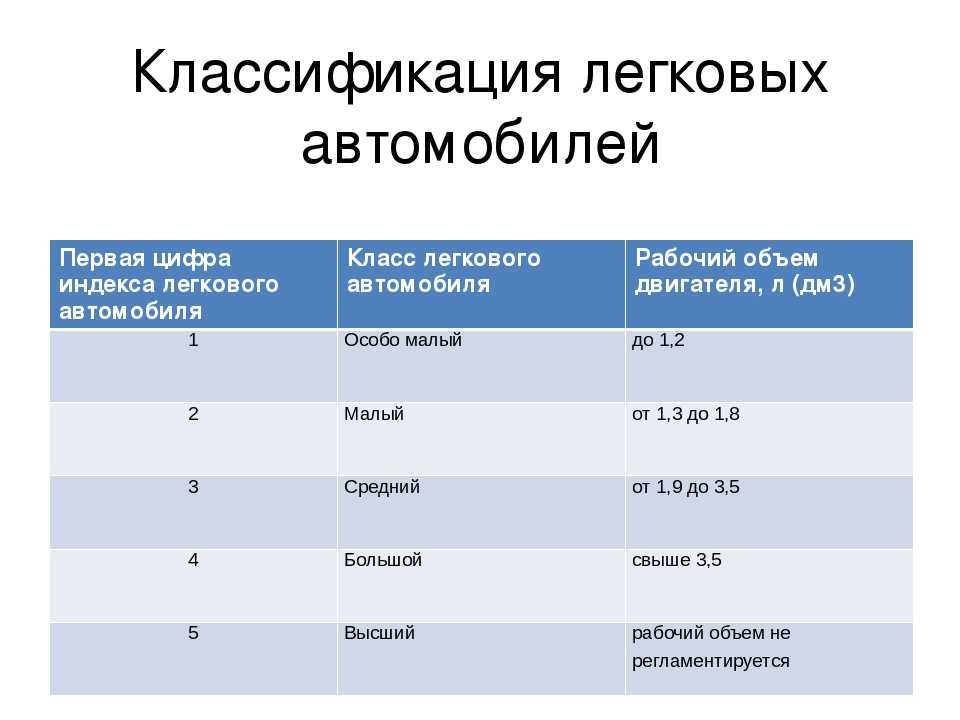 Затем к пространству добавляются новые точки путем предсказания, к какой категории они относятся и какому пространству они будут принадлежать.
Затем к пространству добавляются новые точки путем предсказания, к какой категории они относятся и какому пространству они будут принадлежать.
Преимущества и недостатки
Он использует подмножество обучающих точек в функции принятия решений, что делает его эффективным с точки зрения памяти и очень эффективным в многомерных пространствах. Единственным недостатком метода опорных векторов является то, что алгоритм не дает оценок вероятности напрямую.
Примеры использования
Бизнес-приложения для сравнения динамики акций за определенный период времени
Инвестиционные предложения
Классификация приложений, требующих точности и эффективности
83 2 Узнайте больше об опорном векторе машина в python здесь
Оценка классификатораСамая важная часть после завершения любого классификатора — это оценка для проверки его точности и эффективности.
 Есть много способов, которыми мы можем оценить классификатор. Давайте взглянем на эти методы, перечисленные ниже.
Есть много способов, которыми мы можем оценить классификатор. Давайте взглянем на эти методы, перечисленные ниже.Метод удержания
Это наиболее распространенный метод оценки классификатора. В этом методе данный набор данных делится на две части: тестовый и обучающий наборы 20% и 80% соответственно.
Набор обучающих данных используется для обучения данных, а невидимый тестовый набор используется для проверки его прогностической способности.
Перекрестная проверка
Чрезмерная подгонка — наиболее распространенная проблема, распространенная в большинстве моделей машинного обучения. K-кратная перекрестная проверка может быть проведена, чтобы проверить, подходит ли модель вообще.
В этом методе набор данных случайным образом разбивается на тыс. взаимоисключающих подмножеств, каждое из которых имеет одинаковый размер. Из них один хранится для тестирования, а другие используются для обучения модели.
 Тот же процесс происходит для всех k складок.
Тот же процесс происходит для всех k складок.Отчет о классификации
Отчет о классификации даст следующие результаты: это образец отчета о классификации классификатора SVM с использованием набора данных Cancer_data.
ROC-кривая
Рабочие характеристики приемника или ROC-кривая используется для визуального сравнения моделей классификации, которое показывает взаимосвязь между истинно положительными показателями и ложноположительными показателями. Площадь под кривой ROC является мерой точности модели.
Выбор алгоритмаПомимо описанного выше подхода, мы можем выполнить следующие шаги, чтобы использовать лучший алгоритм для модели
Чтение данных
Создание зависимых и независимых наборов данных на основе наших зависимых и независимых функций
Разделение данных на наборы для обучения и тестирования Дерево решений, SVM и т.
 д.
д.Оценка классификатора
Выберите классификатор с наибольшей точностью.
Хотя выбор наилучшего алгоритма, подходящего для вашей модели, может занять больше времени, чем необходимо, точность — лучший способ сделать вашу модель эффективной.
Давайте посмотрим на набор данных MNIST и воспользуемся двумя разными алгоритмами, чтобы проверить, какой из них лучше всего подходит для модели.
Вариант использованияЧто такое MNIST?
Это набор из 70 000 небольших рукописных изображений, помеченных соответствующей цифрой, которую они представляют. Каждое изображение имеет почти 784 функции, функция просто представляет плотность пикселей, и каждое изображение имеет размер 28×28 пикселей.
Мы создадим предсказатель цифр, используя набор данных MNIST с помощью различных классификаторов.
Загрузка набора данных MNIST
из sklearn.
 datasets импортировать fetch_openml
mnist = fetch_openml('mnist_784')
печать(мнист)
datasets импортировать fetch_openml
mnist = fetch_openml('mnist_784')
печать(мнист)
Вывод:
Изучение набора данных
импортировать matplotlib импортировать matplotlib.pyplot как plt X, y = mnist['данные'], mnist['цель'] случайная_цифра = X[4800] random_digit_image = random_digit.reshape(28,28) plt.imshow (random_digit_image, cmap = matplotlib.cm.binary, интерполяция = "ближайший")
Вывод:
Разделение данных
Мы используем первые 6000 записей в качестве обучающих данных, набор данных достигает 70000 записей. Вы можете проверить, используя форму X и Y. Поэтому, чтобы сделать память нашей модели эффективной, мы взяли только 6000 записей в качестве обучающего набора и 1000 записей в качестве тестового набора.
x_train, x_test = X[:6000], X[6000:7000] y_train, y_test = y[:6000], y[6000:7000]
Перетасовка данных
Чтобы избежать нежелательных ошибок, мы перетасовали данные, используя массив numpy.
 Это в основном повышает эффективность модели.
Это в основном повышает эффективность модели.импортировать numpy как np shuffle_index = np.random.permutation (6000) x_train, y_train = x_train[shuffle_index], y_train[shuffle_index]
Создание цифрового предиктора с использованием логистической регрессии
y_train = y_train.astype (np.int8) y_test = y_test.astype(np.int8) y_train_2 = (y_train==2) y_test_2 = (y_test==2) печать (y_test_2)
Выход:
из sklearn.linear_model импортировать LogisticRegression clf = логистическая регрессия (tol = 0,1) clf.fit(x_train,y_train_2) clf.predict([random_digit])
Вывод:
Перекрестная проверка
из sklearn.model_selection импортировать cross_val_score a = cross_val_score (clf, x_train, y_train_2, cv = 3, скоринг = "точность") среднее()
Вывод:
Создание предиктора с помощью метода опорных векторов
из sklearn импортировать svm клс = svm.
 SVC()
cls.fit (x_train, y_train_2)
cls.predict([random_digit])
SVC()
cls.fit (x_train, y_train_2)
cls.predict([random_digit])
Вывод:
Перекрестная проверка
a = cross_val_score (cls, x_train, y_train_2, cv = 3, скоринг = "точность") среднее()
Вывод:
В приведенном выше примере мы смогли создать предсказатель цифр. Поскольку мы предсказывали, будет ли цифра 2 из всех записей в данных, мы получили ложь в обоих классификаторах, но перекрестная проверка показывает гораздо лучшую точность с классификатором логистической регрессии, а не с классификатором машины опорных векторов.
Это подводит нас к концу этой статьи, где мы узнали о классификации в машинном обучении. Надеюсь, вы поняли все, о чем вам рассказали в этом уроке.
Вам интересно, как продвигаться вперед, зная основы машинного обучения? Взгляните на курс машинного обучения Python от Edureka, который поможет вам встать на правильный путь к успеху в этой увлекательной области.
 Вас подготовят к должности инженера по машинному обучению.
Вас подготовят к должности инженера по машинному обучению.Вы также можете пройти магистерскую программу курса машинного обучения. Программа предоставит вам самую подробную и практическую информацию о приложениях машинного обучения в реальных ситуациях. Кроме того, вы узнаете основы, необходимые для достижения успеха в области машинного обучения, такие как статистический анализ, Python и наука о данных.
Кроме того, если вы хотите развивать свою карьеру с помощью глубокого обучения, вам следует ознакомиться с курсом глубокого обучения. Этот курс дает студентам информацию о методах, инструментах и методах, которые им необходимы для развития их карьеры.
Мы здесь, чтобы помочь вам на каждом этапе вашего пути и разработать учебный план, предназначенный для студентов и профессионалов, которые хотят стать разработчиками Python. Курс разработан, чтобы дать вам преимущество в программировании на Python и обучить вас как основным, так и продвинутым концепциям Python, а также различным платформам Python, таким как Django.
